CSC News
Refining Hurricane Forecasts by Connecting the Dots
 By graphing points in Earth’s roiling atmosphere with the aid of the latest petascale-power technology, scientists collaborating on Department of Energy-funded research say they could improve major seasonal North Atlantic hurricane forecast reliability by more than 25 percent.
By graphing points in Earth’s roiling atmosphere with the aid of the latest petascale-power technology, scientists collaborating on Department of Energy-funded research say they could improve major seasonal North Atlantic hurricane forecast reliability by more than 25 percent.“We ask questions about the end-game of hurricanes: Where will they likely end up in 10 or 15 days?” says Nagiza Samatova, an associate professor in computer science and mathematics at North Carolina State University and a senior research scientist at Oak Ridge National Laboratory.
“We are finding local impacts using global data,” adds Alok Choudhary, Samatova’s collaborator and John G. Searle professor of computer science and electrical engineering at Northwestern University.
After a few years of sleuthing through existing climate records, their work is revealing previously unknown but predictive links between distant places that seem to recur during peak years for hurricane activity.
The project relies heavily on graph theory, a method that creates mathematical links called edges between collections of objects called vertices or nodes. Samatova likens nodes to Facebook users. “Nodes can be people in social networks and the edges can represent any kind of associations between them.”
The research’s theoretical undergirding has support from DOE’s Advanced Scientific Computing Research and Biological and Environmental Research programs. Its application to climate is part of a separate National Science Foundation-supported Expeditions in Computing program.
Samatova’s group initially used graph theory to designate bacterial proteins as nodes and to search for edge relationships with others so that coordinated molecular interactions might produce ethanol or hydrogen.
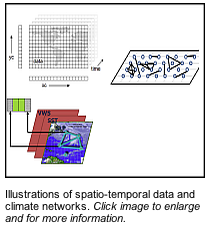 The focus shifted to weather, which can be described as an ensemble of much more massive graphs with nodes representing points on the Earth where climatic data has been collected. Edges link to other nodes that share some climatic similarity.
The focus shifted to weather, which can be described as an ensemble of much more massive graphs with nodes representing points on the Earth where climatic data has been collected. Edges link to other nodes that share some climatic similarity.Samatova explains. “We might see that temperatures in Raleigh (N.C.) and in Knoxville (Tenn.) are highly correlated so we can connect them with an edge having a common temperature profile. Or we may say that Raleigh and Paris have similar humidity profiles in the summer and so may connect them with an edge.”
But applying graph theory to worldwide climate databases is a tall order because, Choudhary says, the available information has “increased by orders and orders of magnitude” over the past 40 years.
Data explosion
Given the global proliferation of weather satellites, balloons, stations and sensors, the challenge of analyzing available information has “exploded,” he says. “While in the past a few megabytes or gigabytes was a huge size, now we have hundreds of terabytes to petabytes. Where in the past maybe only a small number of variables such as atmospheric pressure and temperature could be collected, now we may be able to get many more, such as humidity, wind shear, surface and air temperatures, and various atomic elements such as carbon.”
And that’s naming just a few of the most obvious factors. Working with colleagues at their own institutions and at the University of Minnesota, Northeastern University and North Carolina A&T State University, Choudhary and Samatova have developed methods to apply graph theory to a huge database that draws on 60 years of climate records and may include 50 different variables with 90 million connections.
“You have a humongous, exponential number of combinations and complexities,” Choudhary says.
By analyzing that historical information with devices as powerful as the Oak Ridge Leadership Computing Facility’s Jaguar, a 1.7-petaflops (1.7 million-billion floating point operations per second) supercomputer – now undergoing an upgrade to the multi-petaflop Titan – they have uncovered linkups unidentifiable using conventional global climate models.
Both kinds of analyses start with grid systems that calculate weather conditions at set points of latitude and longitude. But conventional models confine themselves to what Choudhary calls “spatial locality,” or how a block of atmosphere is influenced by neighboring blocks.
Instead, he says, “what we are doing is finding connections across the globe.”
Their graphing, for instance, may discover that one node in the Indian Ocean and another on the Southern California coast somehow share an edge of climatic similarity. But establishing whether such surprising ties are truly climatic signatures or just coincidence requires an elaborate array of cross checking that includes creating graphical sub-networks.
“We start looking,” Samatova says, “at all those years common to high or low North Atlantic hurricane activity and see which climate subsystems have common connections or structures for one group of years but not the other group.”
For this task scientists employ machine-learning networks in which computers and algorithms using preset mathematical rules evolve to capture interesting characteristics from large data swarms.
They also access special libraries where parallel-processing engines can speed climate sensor information through fast enough to avoid bottlenecks, Choudhary says. “You have to be able to access the data as fast as you can. If you can’t, you can’t analyze it.”
Lightening the load
But such exercises inevitably suffer from what the researchers call the “curse of high dimensionality,” meaning there are too many variables to isolate the truly diagnostic trends.
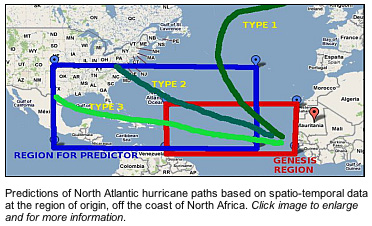
To reduce that load, the team turns to history. “We know that 85 percent of North Atlantic hurricanes originate off of western Africa,” she says, so the researchers narrow their search to features that always show up when hurricanes form there.
“We only choose those features and locations where we already see some signatures,” Samatova explains. “So we can use those features to build a predictor.” Such probing, for instance, has identified one set of climate conditions tying the west coast of Africa with another area over eastern Africa’s Ethiopian highlands. The researchers also have identified other possible linkups outside of Africa but cannot reveal the details because those findings haven’t been published yet.
The researchers claim their method can increase the accuracy of seasonal hurricane activity predictions by more than 25 percent for those bigger peak-year storms originating off Africa. By looking back 60 years for telltale features isolated from hurricane track data, prognosticators can better predict whether a given storm will eventually strike the Gulf region or the United States’ Atlantic coast or instead dissipate in the mid-Atlantic.
“We can use the data and our algorithms to predict which event is most likely,” with a 15 to 20 percent accuracy improvement and a 10- to 15-day forecast lead time, Choudhary says.
Statistical majority voting techniques also could weigh all the past evidence to help prognosticators decide if this will be a high hurricane activity year, Samatova says. But “what we cannot say is exactly which months will be active or not. We only have reliable data for 60 years.” To approach that precision, they’d need data for a few hundred years.
Meanwhile, the group also is targeting other extreme climate-related events such as drought, rainfall and fire. And it is even probing a connection between low-humidity periods and outbreaks of dust-borne meningitis in Africa’s Sahel region. A single outbreak there in 1996 sickened nearly 200,000, with 20,000 fatalities, the World Health Organization reports.
Follow-up work at N.C. State suggests that, depending on location, humidity readings of 40 percent or less might signal the need for preventive vaccinations, Samatova says. Their network data-mining analytical techniques could improve humidity forecasting there by 20 to 30 percent.
-###-
Return To News Homepage